因美纳新一代测序(NGS)目前是人类全基因组测序(WGS)中应用最为广泛的技术,可提供准确、可扩展且经济高效的解决方案,在超过300,000份科学文献中有所应用1。然而,由于基因组存在高度重复或高度同源区域,一小部分基因组仍然难以绘制。
Illumina Complete Long-Read技术(以前称“Infinity”)能够攻克这些难题,并加速访问剩余约5%难以绘制的基因区域。因美纳长读长技术使用专有的文库制备流程,集成可靠的因美纳SBS化学技术和准确快速的DRAGEN分析,以及可扩展的因美纳互联分析软件来获得高性能的长读长数据。
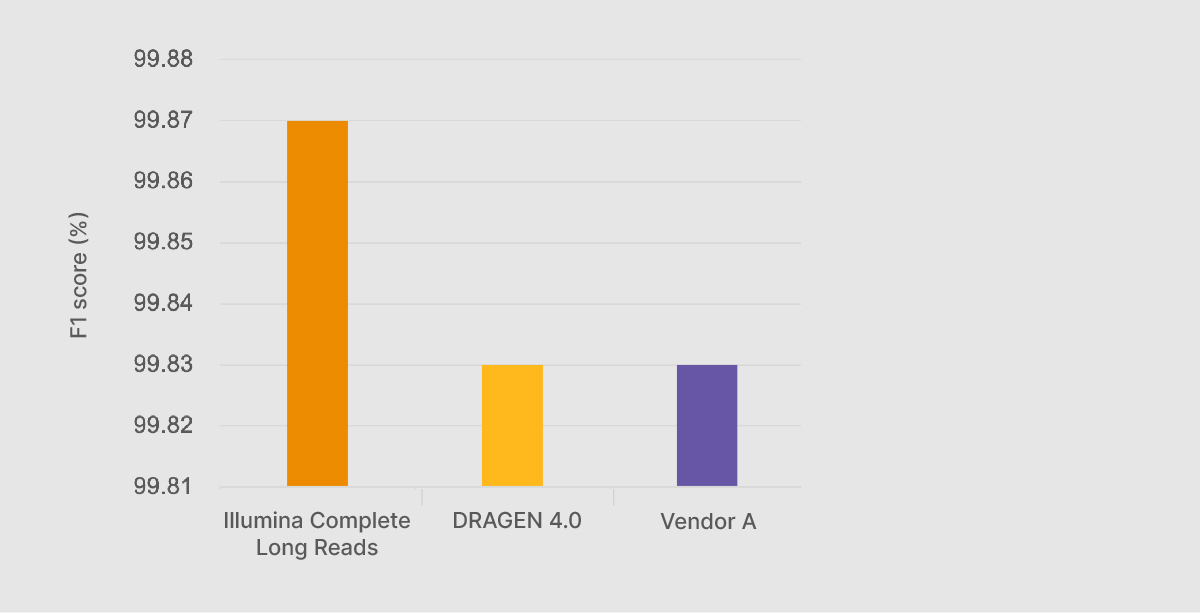
在2022年9月的因美纳基因组学论坛上,因美纳首席科学官Alex Aravanis展示了与PrecisionFDA Truth Challenge v2基准数据集比较获得的Illumina Complete Long Read初步性能数据2。使用Illumina Complete Long Reads和DRAGEN分析获得的F1评分为99.87%(查准率和查全率的复合统计数据),高于任何其他方法,包括市面上的长读长技术(图1)。
与市面上现有的长读长解决方案相比,Illumina Complete Long-Read检测性能优越、操作简便且具有扩展性。该检测方法使用标准的NGS工作流程,可生成N50为6–7 kb的连续长读长数据,针对人类WGS可生成> 30 kb的读长(图2、图3)。高效的文库制备方案只需一天即可完成,并且易于扩展,适用于高通量研究。该实验方案还兼容多种样本类型,DNA起始量仅需50 ng,无需专门的提取、剪切或片段长度筛选。
多种基于Illumina Complete Long-Read检测的产品正在开发中:
- Illumina Complete Long-Read Prep, Human(2023年第一季度推出)专为人类WGS而设计
- Illumina Complete Long-Read Prep with Enrichment,适用于人类WGS,专注于复杂基因区域的靶向长读长数据


Illumina Complete Long-Read检测的强大功能
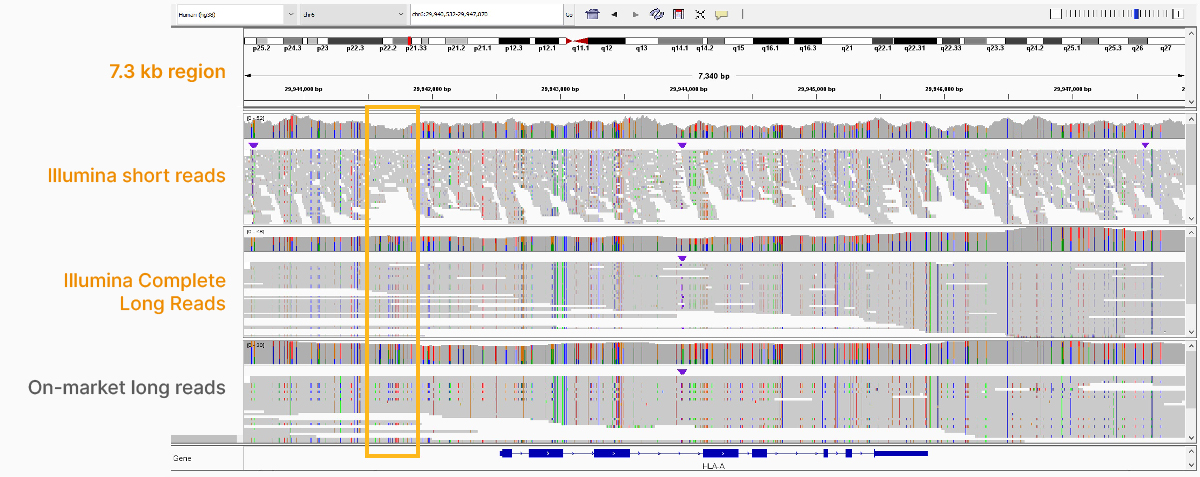
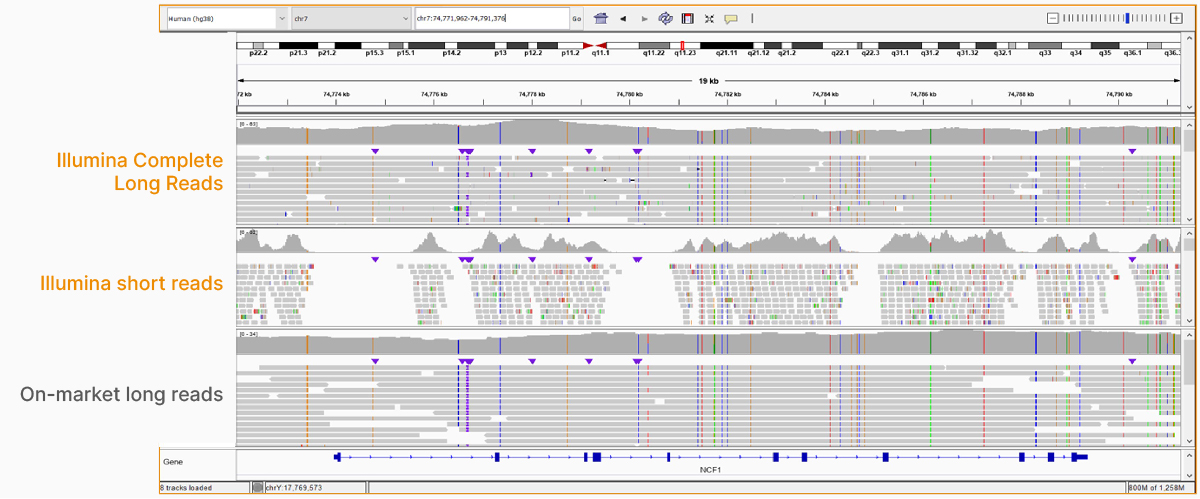
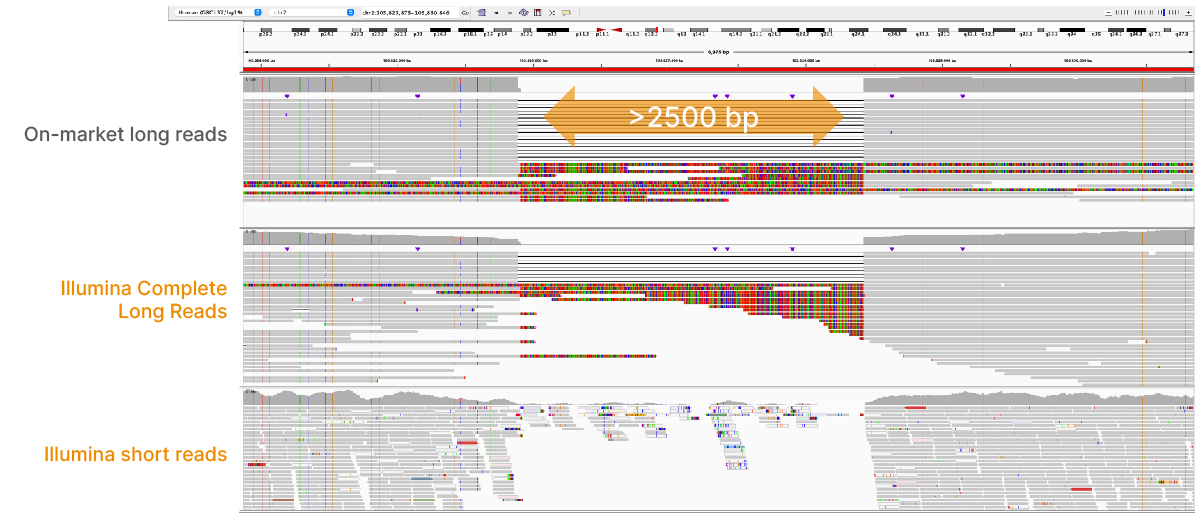
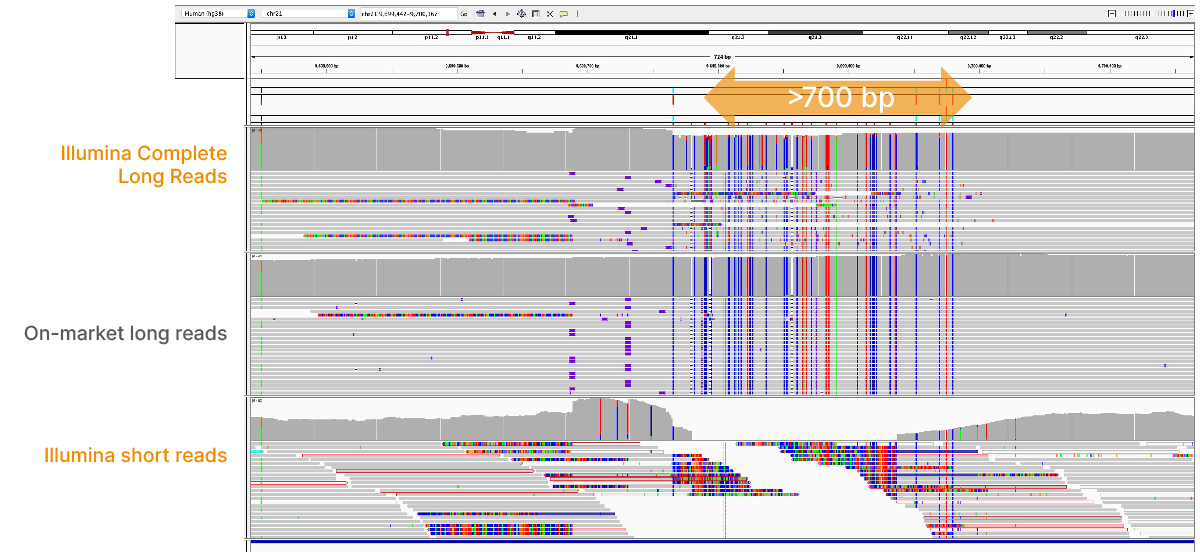
在2022年4月的网络研讨会上,我们展示了因美纳长读长数据在传统的复杂区域中改善比对和变异检出的能力,包括重复区域、高度多态性区域(图4)、假基因和旁系同源物(图5)、大片段插入-缺失变异(indel)(图6)和结构变异(图7)等。
除全基因组检测外,我们还展示了Illumina Complete Long-Read技术是如何与富集方法兼容的(图8)。靶向解决方案将专注于利用更长的读长从已知区域获得更多见解。具有富集功能的后续产品将提供更高的灵活性和可扩展性。

Illumina Complete Long-Read正在加深我们对人类基因的理解
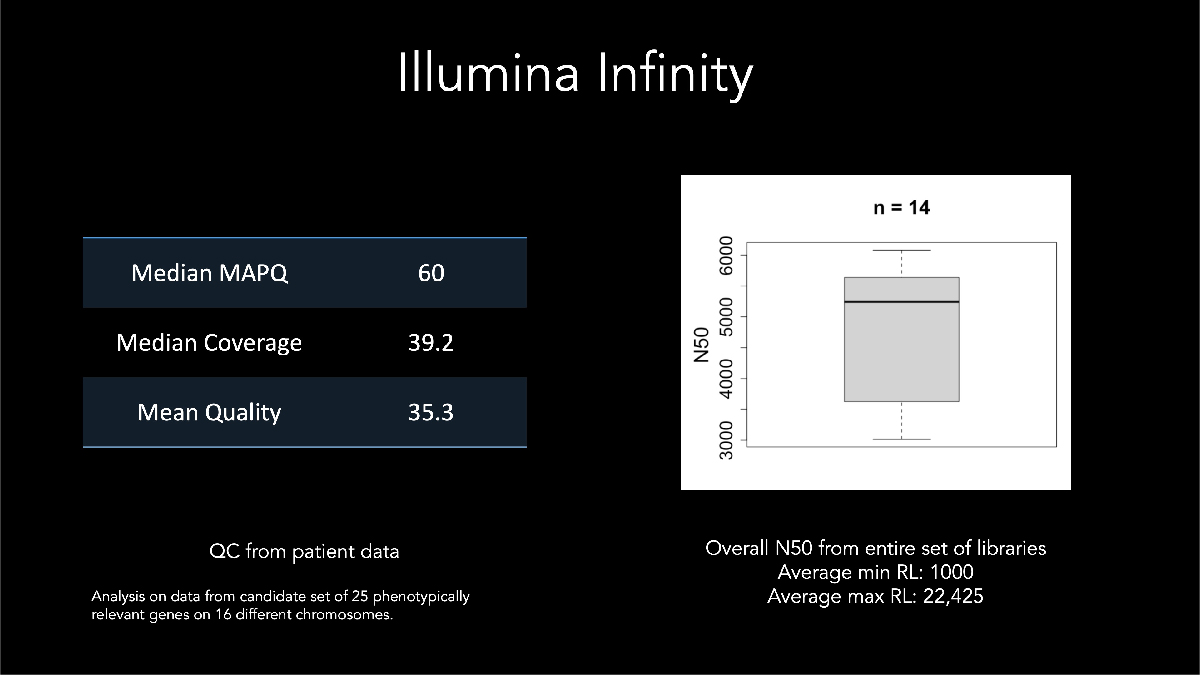
在AGBT 2022主题演讲中,斯坦福医学中心的Euan Ashley博士讲述了如何使用因美纳长读长数据检出和定相遗传病患者样本中的新发变异。Ashley博士着重指出在早期开发检测指标中样本生成的中位数N50 > 5 kb,其中某些读数甚至超过22 kb(图9)。
在2022年因美纳基因组学论坛上,n-Lorem基金会介绍了他们与因美纳合作使用Illumina Complete Long-Read检测对n-Lorem患者样本进行测序的最新进展。由此产生的定相高质量测序能够识别与致病等位基因相关的患者特异性SNP,这对于设计患者特异性反义寡核苷酸至关重要。这些数据支持n-Lorem为患有遗传性纳米罕见病的患者(全球少于30人)寻找个性化的反义寡核苷酸(ASO)药物。
n-Lorem的高级研究主任Tracy Cole博士说:“因美纳Infinity技术的准确度和成本效益对我们来说非常重要,但对我们急需帮助的患者来说更为重要。它能够准确检出罕见变异,并将数据定相解析为单倍型,这有助于为ASO发现提供信息,确保我们能利用正确的数据来做出重要的药物发现决策。”
因美纳将继续致力于扩展其支持的应用范围,并提供更完整、更全面的基因组视图。
参考文献
- Data calculations on file, Illumina, Inc. 2022.
- PrecisionFDA Truth Challenge V2. precision.fda.gov/challenges/10. Published 2020. Accessed September 20, 2022.